Web server
Toward Enduring Web Citations
An attempt to solve the twin problems of impermanence and imprecision.
n. A citation that combines a textual reference with a durable hyperlink to that exact passage in a preserved copy of the source.
v. (–cited, –citing) To create a citation by joining a selected text passage to a permanent, pinpoint hyperlink of its archived source.
Before going into the mechanics, see it in action:

Here’s the deepcite I created there—try the link for yourself:
The Twin Flaws of a Standard Hyperlink
The architecture of the web is fundamentally at odds with the demands of lasting citation. Any link we use as a reference is undermined by two distinct problems: one of permanence, the other of precision.
The permanence problem—link rot—is well-known. A normal hyperlink is a fragile, hopeful pointer to a resource you don't control. Pages change, URL schemes evolve, and critical information simply disappears. The Internet Archive has been fighting this battle for decades.
The precision problem is more subtle, a chronic friction we’ve just grudgingly accepted. A link to a 10,000-word article isn’t a citation; it’s a research assignment you’ve hoisted upon your reader. In effect they are asked to (a) take you at your word, (b) try to guess the right keywords for a ⌘ F search with whatever contextual clues you’ve provided, or (c) just resign themselves to reading the document in full.
The web has an emerging tool for the precision problem in the text fragment URL. By appending #:~:text=... to the end of a link, you can direct nearly every modern web browser to scroll to and highlight a specific passage on that page. At first blush, this recent W3C standard seems incredibly useful. Provide a colleague the precise pincite to one consequential fact you spot on line 2416 of a dense environmental report. Or point your future self back to a key insight toward the end of an obscure scientific study that took you multiple reads to appreciate its significance. This looks promising...
But on its own, this technology only exacerbates the permanence problem. It creates a citation so specific that a single punctuation fix on the live page will break it—a phenomenon one might aptly call “fragment rot.”
A truly useful web citation needs to solve both problems at once: it must point precisely to the relevant portion of a cited source, and it must do it enduringly. For that to happen, the source itself must be frozen in time, exactly as it appeared when the citation was made.
Calling All Archivists
Inspired by my earlier work on a similar script for DEVONthink (which also has significant new features and improvements as I'll detail in a follow up post), I saw the potential a text fragment tool could have. I enlisted my trusty AI coding assistant, and within five minutes, I had a working proof of concept. But my initial success was short-lived. I experienced fragment rot firsthand after just a few uses, and then again a few days later. The theoretical risk I’d anticipated was a practical, frequent reality.
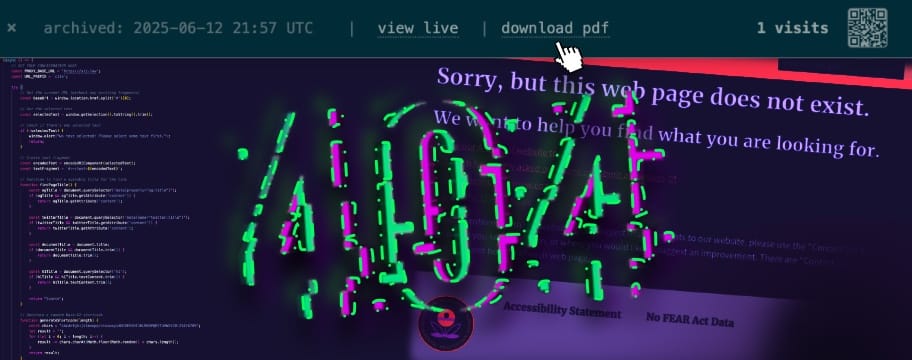
This technical frustration soon collided with a much larger concern. Immediately after the presidential inauguration on January 20, 2025, information began disappearing from federal government websites—first sporadically, very soon systematically. Databases and other resources conservationists have long relied on from agencies like the EPA and NOAA, among others, abruptly went dark.
As a public interest environmental lawyer, my work is built on this data. My cases under the Endangered Species Act (ESA), Clean Water Act (CWA), and National Environmental Policy Act (NEPA—RIP) depend on a stable, verifiable administrative record. This wasn’t just another vaguely-menacing news item portending yet more symbolic violence on the Rule of Law. It represented (and still represents) a clear, concrete, and immediate threat to my clients' interests and to the science-based, mission-driven advocacy my colleagues and I have built our careers on.
I had already explored the world of self-hosting enough to have come across ArchiveBox, an open-source tool that creates high-fidelity, personal archives of web content. Its recent beta API made it the perfect engine. But ArchiveBox alone wasn’t sufficient. The URL for each archived snapshot includes a timestamp with microsecond accuracy, making it impossible to predict from the client-side. I needed a custom bridge to sit between my browser and my archive.
The Web Deepcite Tool
My solution is composed of two parts that work together: a script that runs in your browser, and an optional backend you can host yourself.
1. Browser Deepciter (client)
The heart of the system is a single JavaScript file. I run it in Orion Browser using its excellent Programmable Button functionality with a keyboard shortcut, but it works just as well as a standard bookmarklet in any other modern browser.
When you select text on a page and run the script as-is, it assembles and stores in your system clipboard a deepcite formatted in rich text looking like this:
note: the cite is hyperlinked with text fragments to the original:
https://example.com/#:~:text=This%20domain%20is ...When you configure the script by pointing PROXY_BASE_URL to your self-hosted backend, and specifying URL_PREFIX to match your backend’s configuration, it creates a deepcite that looks the same, except that the citation's hyperlink points to the archived webpage.
2. Self-Hosted Backend (server)
The backend pairs a standard ArchiveBox instance with a FastAPI server that I wrote to act as a smart proxy with basic URL shortening / analytics functionality built in. When you create a deepcite, the backend tells ArchiveBox to save a 100% self-contained archive of the page using Singlefile.
When the link is visited, the proxy serves that file after injecting a minimalist banner at the top to indicate:
- archival date;
- any delay between when the citation was made and when the page was archived (this can happen if ArchiveBox had a long job queue or was unresponsive);
- link to archived PDF of page;
- link to original / live page; and
- QR code for archival URL.
Try First On My Demo Server
Setting up a self-hosted server can be a project. To help decide if this is a workflow you'd find useful, you can point the client script to my public demo instance. To do this, configure the variable at the top of the JavaScript file:
PROXY_BASE_URL = 'https://cit.is'Getting Your Own Setup Running

If you're as excited about this as I am, and want your very own permanent private archival deepciter, head over to my open source code repository to get started:
The README.md file in that repository provides the canonical step-by-step instructions. The setup process should be familiar to anyone who has dabbled in self-hosting. You will use a standard .env file to configure the ArchiveBox Docker container, and a config.yaml file to tell the proxy script where to find your ArchiveBox instance and how to behave. Once configured, you run the services with docker compose and the proxy script via Python.
Next Steps
This toolkit is already a core part of my own workflow, but I am considering several future improvements and welcome feedback. I'm currently mulling adding the Internet Archive as an alternative to Archivebox, finding a creative way to bypass the need for a server script (perhaps by combining Internet Archive with an API call to a link shortening service), integrating deepcite functionality directly into ArchiveBox (i.e. by forking that project), and building browser extensions for a more polished UX than bookmarklets.
The web's citation problems aren't going away—if anything, the recent wave of government data disappearing has made clear how fragile our digital references really are. Deepcite won't solve every corner case, and setting up your own archive does require some technical effort. But for researchers, writers, and lawyers who depend on precise, durable evidence, the investment in a system you control is, I believe, a necessary one.
UPDATES
2025.06.20
I've added support for using SingleFile directly and bypassing ArchiveBox. In my testing so far SingleFile is faster, more reliable, simpler, and uses a lot less space. I.e., a win/win/win/win. SingleFile is therefore now the default mode.
2025.06.22
I'm excited to share that I'm busy building this out as a subscription service at cit.is. Stay tuned for announcements about a public beta soon. Meantime, please note I'm moving the demo deepcites from https://sij.law/cite/ to https://cit.is/ .
{kind=link}
Getting Clever with Caddy and Conduwuit / Matrix
A deep dive into We2.ee's Caddy configuration, handling Matrix federation, offering profile and room redirection shortlinks, and combining multiple services on a single domain.
My post earlier this evening discussed generally how Caddy has made self-hosting multiple web services a breeze. Here I want to build on that and look specifically at the Caddy configuration I use for We2.ee, the public Matrix homeserver I run and have posted about already.
The complete Caddyfile entry is available here. Let's look closer at a few key sections. First, you'll see a series of redirection handlers like this:
handle /about {
redir https://sij.law/we2ee/ permanent
}This one simply redirects we2.ee/about to sij.law/we2ee . This allows me to create authoritative "About" URL on the we2.ee domain but host the actual page here on my blog – saving me having to host a whole separate CMS just for We2.ee, and potentially lending credibility to We2.ee through my professional online presence here.
Next, you'll see some more redirection handlers that rely on regular expressions ("regex"):
# Handle Matrix-style room redirects
@matrix_local_room {
path_regexp ^/@@([^:]+)$
}
redir @matrix_local_room https://matrix.to/#/%23{re.1}:we2.ee permanent
# Handle Matrix-style room redirects with custom domains
@matrix_remote_room {
path_regexp ^/@@([^:]+):([^/]+)$
}
redir @matrix_remote_room https://matrix.to/#/%23{re.1}:{re.2} permanent
# Handle Matrix-style user redirects
@matrix_local_user {
path_regexp ^/@([^:]+)$
}
redir @matrix_local_user https://matrix.to/#/@{re.1}:we2.ee permanent
# Handle Matrix-style user redirects with custom domains
@matrix_remote_user {
path_regexp ^/@([^:]+):([^/]+)$
}
redir @matrix_remote_user https://matrix.to/#/@{re.1}:{re.2} permanentThese are particularly efficient—they allow for much shorter links for Matrix rooms and user profiles that redirect to the Matrix.to service. For example:
- we2.ee/@sij redirects to
matrix.to/#/@sij:we2.ee(saving 12 characters) - we2.ee/@sangye:matrix.org redirects to
matrix.to/#/@sangye:matrix.org(saving 5 characters) - we2.ee/@@pub redirects to
matrix.to/#/#pub:we2.ee(saving 11 characters) - we2.ee/@@matrix:matrix.org redirects to
matrix.to/#/#matrix:matrix.org(saving 4 characters)
Next you'll see the handlers for the actual underlying services, Conduwuit and Element:
# Handle Conduwuit homeserver
handle /_matrix/* {
reverse_proxy localhost:8448
}
# Handle federation
handle /.well-known/matrix/server {
header Access-Control-Allow-Origin "*"
header Content-Type "application/json"
respond `{"m.server": "we2.ee"}`
}
# Handle client discovery
handle /.well-known/matrix/client {
header Access-Control-Allow-Origin "*"
header Content-Type "application/json"
respond `{
"m.homeserver": {"base_url": "https://we2.ee"},
"org.matrix.msc3575.proxy": {"url": "https://we2.ee"}
}`
}
# Handle MSC1929 Admin Contact Information
handle /.well-known/matrix/support {
header Access-Control-Allow-Origin "*"
header Content-Type "application/json"
respond `{
"contacts": [
{
"matrix_id": "@sij:we2.ee",
"email_address": "[email protected]",
"role": "m.role.admin"
}
],
"support_page": "https://we2.ee/about"
}`
}
# Handle Element webUI
handle {
reverse_proxy localhost:8637
}This part of the Caddy configuration block:
- serves up the actual Matrix homeserver (powered by conduwuit) at We2.ee
- provides the necessary endpoints for federation
- provides the MSC1929 endpoint for handling abuse reports, etc.
- serves up an Element web interface for accessing the Matrix homeserver directly at We2.ee
I hope some of this is useful for folks running their own Matrix homeservers or anyone interested in seeing how Caddy configurations can be structured for more complex setups.
Simplifying Web Services with Caddy
Running multiple web services doesn't have to be complicated. Here's how Caddy makes it simple by handling reverse proxying and HTTPS certificates automatically, plus a script I use to set up new services with a single command.
After my recent posts about We2.ee, Lone.Earth, Earth.Law and that pump calculator project, several folks asked about managing multiple websites without it becoming a huge time sink. The secret isn't complicated—it's a neat tool called Caddy that handles most of the tedious parts automatically.
Understanding Reverse Proxies
Traditionally, web servers were designed with a simple model: one server running a single service on ports 80 (HTTP) and—more recently as infosec awareness increased—443 (HTTPS). This made sense when most organizations ran just one website or application per server. The web server would directly handle incoming requests and serve the content.
But this model doesn't work well for self-hosting. Most of us want to run multiple services on a single machine - maybe a blog like this, a chat service like We2.ee, and a few microservices like that pump calculator. We can't dedicate an entire server to each service—that would be wasteful and expensive—and we can't run them all on ports 80/443 (only one service can use a port at a time).
This is where reverse proxies come in. They act as a traffic director for your web server. Instead of services competing for ports 80 and 443, each service runs on its own port, and the reverse proxy directs traffic for
- A blog to port 2368
- A Mastodon instance to port 3000
- An uptime tracking service to port 3001
- A code hub to port 3003
- An encrypted chat service to port 8448
- DNS-over-HTTPS filter and resolver on 8502
- A Peertube instance to port 9000
- An LLM API to port 11434
- ... etc.
When someone visits any of your websites, the reverse proxy looks at which domain they're trying to reach and routes them to the right service. That's really all there is to it—it's just routing traffic based on the requested domain.
Why Caddy Makes Life Easier
Caddy is a reverse proxy that manages this well and also happens to take care of one of the biggest headaches in web hosting: HTTPS certificates. Here's what my actual Caddy config looks like for this blog:
sij.law {
reverse_proxy localhost:2368
tls {
dns cloudflare {env.CLOUDFLARE_API_TOKEN}
}
}
This simple config tells Caddy to:
- Send all traffic for sij.law to the blog running on port 2368
- Automatically get HTTPS certificates from Let's Encrypt
- Renew those certificates before they expire
- Handle all the TLS/SSL security settings
If you've ever dealt with manual certificate management or complex web server configurations, you'll appreciate how much work these few lines are saving.
Making Domain Setup Even Easier
To streamline things further, I wrote a script that automates the whole domain setup process. When I was ready to launch that pump calculator I mentioned in my last post on the open web, I just ran:
cf pumpcalc.sij.ai --port 8901 --ip 100.64.64.11
One command and done—cf creates the DNS record on Cloudflare and points it to the IP of the server running Caddy, creates a Caddy configuration that reverse proxies pumpcalc.sij.ai to port 8901 on my testbench server (which has the Tailscale IP address 100.64.64.11), and handles the HTTPS certification.
If you want to try this script out yourself, see the more detailed documentation at sij.ai/sij/cf, and by all means have a look at the Python code and see how it works under the hood.
Getting Started
- Start by installing Caddy on your server
- Create a config for just one website
- Let Caddy handle your HTTPS certificates
- Add more sites when you're ready
Start small, get comfortable with how it works, and expand when you need to. Ready to dig deeper? The Caddy documentation is excellent, or feel free to reach out with questions.